Čas od času se v diskusích objeví prosba o prošetření výpisu ze smartu. A co hůř, někteří lidé dokonce doporučují používat různé programy od výrobců disků, které mají nějak odhadnout zdraví jejich výrobků. V tomto článku si ukážeme jak rozeznat zdravý disk od vadného z výpisu smart. Tento článek pojednává o rotačních discích. U SSD jsou další atributy, které nejsou předmětem tohoto článku.
Technologie SMART
Self-Monitoring, Analysis and Reporting Technology – interní systém implementovaný v disku pro včasné varování před jeho selháním. SMART má zajistit, že OS (a sekundárně i uživatel) se včas dozví o selhávajícím disku. Není to samospásné, SMART nevaruje vždy (asi 40% případů nepodchytí), ale když už varuje, tak je potřeba to brát vážně.
Co znamená výpis smart atributů
Pro výpis smart atributů se v linuxu nejlépe hodí příkaz smartctl. Ve windows je potřeba použít například Crystal Disk Info. Pozor, ne každý program, který tvrdí, že zjistí stav disku jej skutečně zjistí. Jak uvidíme dále, je potřeba umět číst smart atributy včetně RAW hodnot.
Pojdme si tedy vypsat atributy:
# smartctl -A /dev/sda === START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 200 200 051 Pre-fail Always - 0 3 Spin_Up_Time 178 176 021 Pre-fail Always - 4075 4 Start_Stop_Count 100 100 000 Old_age Always - 103 5 Reallocated_Sector_Ct 200 200 140 Pre-fail Always - 0 7 Seek_Error_Rate 200 200 000 Old_age Always - 0 9 Power_On_Hours 028 028 000 Old_age Always - 53201 10 Spin_Retry_Count 100 100 000 Old_age Always - 0 11 Calibration_Retry_Count 100 100 000 Old_age Always - 0 12 Power_Cycle_Count 100 100 000 Old_age Always - 101 192 Power-Off_Retract_Count 200 200 000 Old_age Always - 39 193 Load_Cycle_Count 200 200 000 Old_age Always - 63 194 Temperature_Celsius 111 097 000 Old_age Always - 36 196 Reallocated_Event_Count 200 200 000 Old_age Always - 0 197 Current_Pending_Sector 200 200 000 Old_age Always - 0 198 Offline_Uncorrectable 200 200 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 200 200 000 Old_age Always - 0 200 Multi_Zone_Error_Rate 200 200 000 Old_age Offline - 0
Nejprve si projdeme sloupce:
ID– identifikátor atributu (nezajímá nás)ATTRIBUTE_NAME– asi jasnéVALUE,WORST,THRESH– viz další text – nezajímá nás, ale většina programů to zobrazujeRAW_VALUE– jediné hodnoty, které nás skutečně zajímají (v některých programech je těžké je zobrazit – takovým se vyhněte)
Smart hlídá několik atributů, každý výrobce má jinou sadu a jiný počet. Ty důležité atributy (dostaneme se k nim), jsou ale společné pro všechny výrobce.
Teď něco k hodnotám. Hodnota VALUE by mohla mást názvem, že se jedná o naměřenou hodnotu, že sama o sobě něco znamená (někteří lidé jsou vyděšeni tím, že disk má přes 100°C apod.). Hodnota VALUE je přepočítaná hodnota dle nějakého vzorce.
Čím vyšší, tím lepší, se zhoršením parametrů by měla klesat.
WORST je nejhorší dosažená hodnota VALUE za celou dobu života disku (kromě
toho, že se to dá vymazat). THRESH je práh, pokud hodnota VALUE klesne
(zhorší se parametry) pod THRESH, tak je špatně.
Tolik teorie. Hodnota VALUE tedy nic neznamená, je to nějak počítaná hodnota, vzorec není veřejný, je to věc firmware disku. Takže úplně k ničemu.
Nehledě na to, že některé disky mají rozsah VALUE 253-0, jiné 200-0, další 100-0. Tenhle disk uvedený v příkladu má některé atributy 200 a jiné 100.
Takže konkrétní hodnota parametru VALUE je naprosto nezajímavá a nic sama o sobě neříká. Jediná vypovídací hodnota je nenadálé rychlé snížení hodnoty. Ale to stejně poznáme z RAW_VALUE.
Závěr tedy: Na VALUE, WORST, THRESH se vyprdněte. A na programy, které neumí zobrazit RAW_VALUE taky.
RAW_VALUE je to, co nás zajímá. Skutečné hodnoty, nic přepočítaného. Počet sektorů je zkrátka počet sektorů, teplota je prostě teplota. (Neplatí pro všechny některé atributy, které nás až tak nezajímají, ukazují v RAW_VALUE hodnoty složené – typicky Raw_Read_Error_Rate u seagate disků, hodnota bývá extrémě vysoká, ale je to hodnota udávající několik parametrů zároveň).
Takže které jsou ty atributy, které by nás měly zajímat?
Zejména tyto (odstranil jsem nezajímavé sloupce):
ID# ATTRIBUTE_NAME RAW_VALUE 5 Reallocated_Sector_Ct 0 196 Reallocated_Event_Count 0 197 Current_Pending_Sector 0 198 Offline_Uncorrectable 0
Jedná se o vadné sektory.
Offline_Uncorrectable– vadné neopravitelné sektoryCurrent_Pending_Sector– sektory, které jsou „divné“ a čekají na další
posouzení. Může se stát, že zmizí a hodnota bude zpět nula, nebo se z nich stane neopravitelný sektor. Takový sektor může vzniknout třeba při výpadku proudu, ale na zdravém běžícím systému jen tak sami od sebe nevzniknou.Reallocated_Sector_CtaReallocated_Event_Count– počet realokovaných sektorů. Každý disk má hromadu (přesné číslo se opět nikde nedočtete), sektorů navíc a je schopen vadný sektor přemapovat na nějakého náhradníka.
Všechny tyhle atributy by měly měly mít hodnotu nula. Já disk vyměňuji a posílám na reklamaci tehdy, pokud je jakákoliv hodnota nenulová. I pending. Protože stroje nevypínám a nemá to jak jinak vzniknout.
Následující hodnoty jsou více méně pro info (opět jsem odstranil nezajímavé sloupce):
ID# ATTRIBUTE_NAME RAW_VALUE 9 Power_On_Hours 53201 194 Temperature_Celsius 36 199 UDMA_CRC_Error_Count 0
Power_On_Hours– počet naběhaných hodin. Jo, tenhle disk už má něco za sebou (asi tak 6 let nonstop provozu).Temperature_Celsius– teplota, některé disky ukazují i nejvyšší teplotu za
celou dobu životnosti disku.UDMA_CRC_Error_Count– chyby CRC při přenosu, většinou to ukazuje na chybu kabelu (nebo elektroniky).
Tehle disk má sice své naběháno, ale jinak je úplně zdravý.
Pravidelné testování
Disk podporující smart umí otestovat sám sebe. Jsou definované dva typy testů, jeden short (měl by běžet asi minutu) a druhý long, který otestuje celý povrch disku (a trvá tedy tak dlouho, kolik času je potřeba k přečtení všech bloků).
Test lze spustit pomocí:
smartctl -t short /dev/sda
Výsledek nebo průběh (pokud test stále běží), vidíme na výpisu:
smartctl -l selftest /dev/sda
Ukázový výstup:
SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed without error 00% 53189 - # 2 Short offline Completed without error 00% 53165 - # 3 Short offline Completed without error 00% 53141 - # 4 Short offline Completed without error 00% 53130 - # 5 Extended offline Completed without error 00% 53098 - # 6 Short offline Completed without error 00% 53094 - # 7 Short offline Completed without error 00% 53070 - # 8 Short offline Completed without error 00% 53046 - # 9 Short offline Completed without error 00% 53022 - #10 Short offline Completed without error 00% 52998 - #11 Short offline Completed without error 00% 52974 - #12 Short offline Completed without error 00% 52951 - #13 Extended offline Completed without error 00% 52930 -
Pečlivý čtenář si všimne, že testy se na tomto disku provádějí pravidelně a že je jistě nepouštím ručně. K pravidelnému testování slouží služba smartd, a lze jej nastavit v /etc/smartd.conf:
DEVICESCAN -d removable -n standby -m root -s (S/../.././02|L/../../6/03)
Jedná se o parametr -s, pro info o nastavení časů viz man smartd.conf.
Tímto parametrem je zajištěno, že služba smartd bude pravidelně testovat všechny nalezené disky (v tomto případě včetně přenosných disků – za normálních okolností se smartd ukončí po vyjmutí sledovaného zařízení, parametr -d removable způsobí, že smartd bude pokračovat i po vyjmutí disku nebo jeho opětovného připojení).
Pokud disk testem neprojde, ve výpisu se objeví hláška o chybě (na konkrétním sektoru) a měl by přijít email s varováním (nastavení smartd je mimo rozsah tohoto článku).
badblocks
Další oblíbeným programem na testování disků je badblocks. Jak již název napovídá program má hledat vadné sektory. Může běžet ve dvou režimech, první je read-only, druhý je write (který zničí data na daném disku, protože jej celý přepíše).
Hodně adminů je po úspěšném průběhu badblocks přesvědčeno, že disk je v pořádku. Ale nemusí být. Jak jsme si již řekli, disk může vadné sektory realokovat (pokud má ještě z čeho brát). Takže disk může během badblocks (zejména write) testu vadné sektory realokovat a výsledek testu bude OK a přitom je disk vadný.
Po jakémkoliv testu je tedy nutné zkontrolovat smart atributy disku. Samotný badblocks test je sám o sobě nevypovídající (pokud selže, tak je disk opravdu na reklamaci, pokud nikoliv, je potřeba se ještě podívat do smartu).
Díky Michalovi za pěkné doplnění.
Programy od výrobců disků
Nedávno někdo v diskusi na FB doporučoval pro test disku použít program od výrobce disku. Konkrétně SeaTools (od Seagate). Tak jsem se na něj podíval. Mám tu vadný disk od výrobce Seagate:
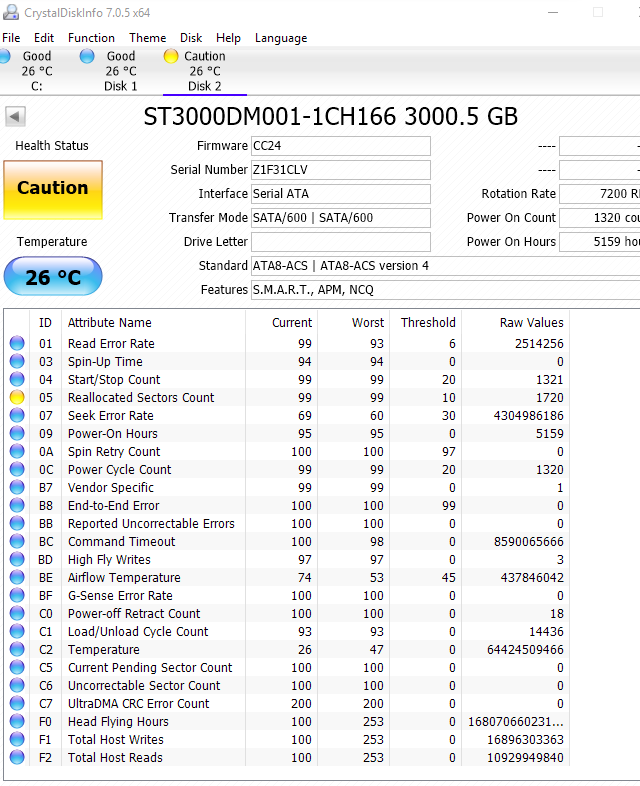
Výpis z programu Crystal Disk Info (který ukazuje i raw values) jasně ukazuje, že disk je vadný. Má 1720 vadných sektorů, všechny se podařilo realokovat. Rovnou vidíme, že i téměř dva tisíce vadných sektorů disk považuje za běžnou věc, protože hodnota VALUE klesla z 100 na 99. Tedy o jedno procento. Práh je od výrobce nastaven na 10. Pokud by to tedy bylo lineární, tak disk by sám sebe považoval za vadný až po vyčerpání 154800 sektorů. (Ale přesnou funkci počítání VALUE samozřejmě neznáme.)
A co na to říká SeaTools?
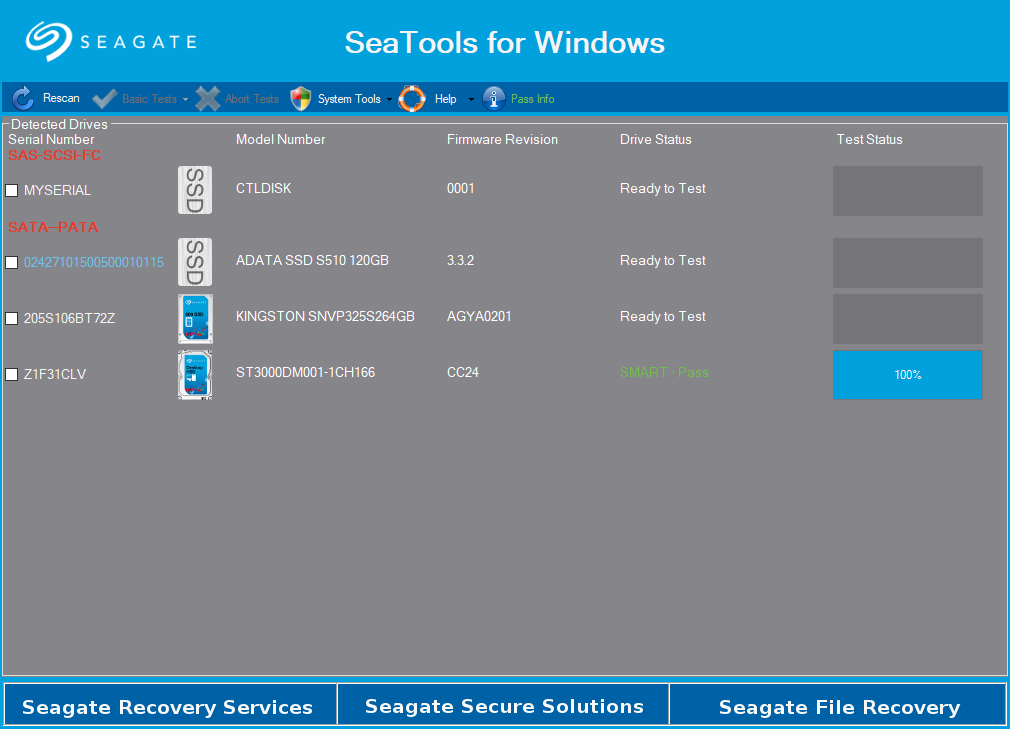
Disk prošel.
Moje doporučení je tohle prostě nepoužívat. Na kontrolu smart atributů se nejlépe hodí smartctl. S programy od výrobců disků mám jen špatné zkušenosti. SeaTools spadne kdykoliv, kdy se chci podívat do sekce advanced test. Na BasicTests zase neukazuje vůbec nic (rozhodně ne raw hodnoty).
U programu od WD se mi stala horší věc. Na doporučení od WD jsem prokazatelně vadný disk (hromada vadných sektorů) projel programem od WD (lifeguard cosi), ten prohlásil, že disk je v pořádku (každý disk je vždycky v pořádku). A co bylo horší, vymazal smart tabulku, takže disk byl po tomto „testu“ čistý jako lilie. Dle smartu byl jako nový.
Kdybych byl svině, tak ten disk jako nový prodám v bazaru (ale svině nejsem), nepochybuji o tom, že to takto lidi i obchody dělají (tzv. „rozbalené“ zboží). Výsledkem tohoto testu tedy bylo, že jsem měl v ruce vadný disk, ale neměl jsem to jak prokázat. Perfektní program.