 Minule jsme si postavili počítadlo, dneska si něco vyrenderujeme (asi tak 48x * 3) v PovRAY.
Minule jsme si postavili počítadlo, dneska si něco vyrenderujeme (asi tak 48x * 3) v PovRAY.
PovRAY je renderer s vlastním jazykem vycházejícím z jazyka C. Veškeré objekty se definují v textovém souboru. Na rozdíl od jiných raytracerů nedefinuje geometrické objekty jako soustavu trojúhelníků, ale pracuje s matematickými definicemi daného tělesa. Tedy koule je skutečně koule a nikoliv n-hran. Složitějších tvarů se dosahuje pomocí množinových operací jako skládání, rozdíl, doplněk. Implementuje skutečný raytracing, radiozitu, a modelování fotonů.
Pro tento článek je důležité, že od verze 3.7 umí také renderovat ve více vlánkech. V tomto článku si zkusíme na 8 jádrovém Ryzenu (16 SMT jader) vyrenderovat dvě scény, které nejsou sice z nejkrásnějších, ale na benchmark se hodí. Jedna scéna je čistý raytracing, druhá potom používá i radiozitu.
Renderoval jsem ukázkové soubory v defaultním nastavení s ruzným počtem threadů (parametr +WT). A to do počtu 24 threadů.
GlassChess
První scéna jsou skleněné šachové figurky. Pamatuji si, jak jsem na to kdysi čekal půl dne (bez AA a v malém rozlišení). Dnes záležitost na 15s.

Na prvním grafu vidíme závislost výkonu (zde prezentovaný jako počet pixelů za sekundu) na nastaveném počtu pracovních vláken:

Už na první pohled vidíme 3 různé oblasti (do 8 vláken, do 16 vláken, do 24). Přidáme si k tomu trendy:
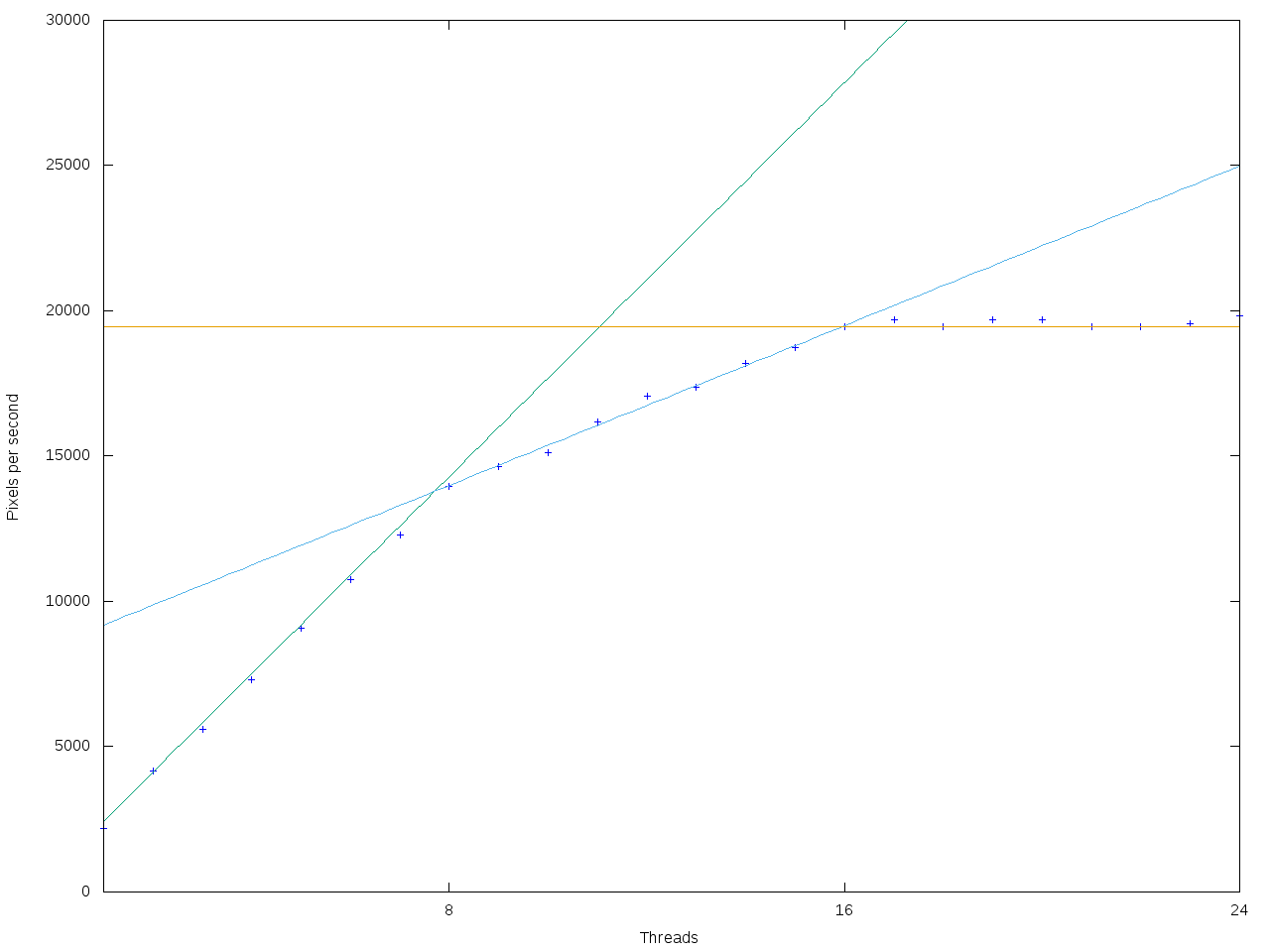
Procesor do 8 vláken škáluje krásně lineárně. Do 16 vláken (kde je opět nárůst výkonu lineární) není nárůst výkonu sice tak velký, ale stále dostaneme o 40% vyšší výkon. Od 17 vláken dál už výkon nijak neroste ale ani neklesá. Co to znamená. Jednak context switching nepřináší nijak velkou režii a s konkrétním počtem vláken si není potřeba dělat velké starosti. Dále, a tady nevím přesně, jaké operace PovRay dělá, čekal bych, že to bude čistě integer, pokud se nepletu, tak Ryzen umí dělat část integer operací i na FP jednotce. Je tedy možné, že část FP jednotek je jedním vláknem povraye nevyužitá a SMT tam narve druhé vlákno. Nebo se jen čeká na výlet do cache. Těžko říct.
Patio Radiosity
Druhá scéna používá radiozitu. PovRay to renderuje ve dvou průchodech, nejdříve je na řadě distribuce energie a potom na to pustí raytracing. Oba kroky jsou na sobě nezávislé a raytracing musí čekat.

Zde vlastně vidíme totéž.
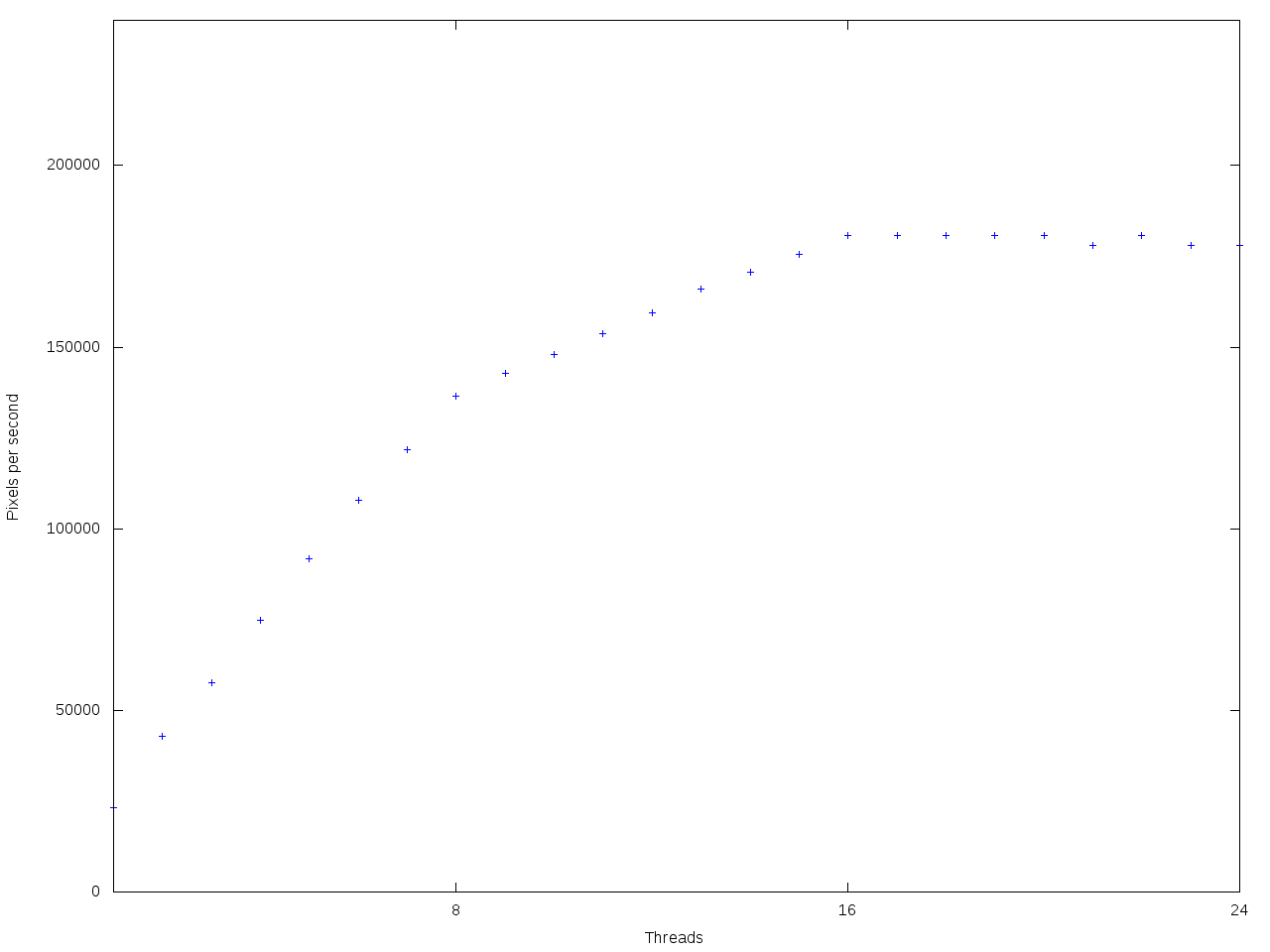
Oblast lineárního škálování do 8 vláken, do 16 vláken a plato nad 16 vláken.
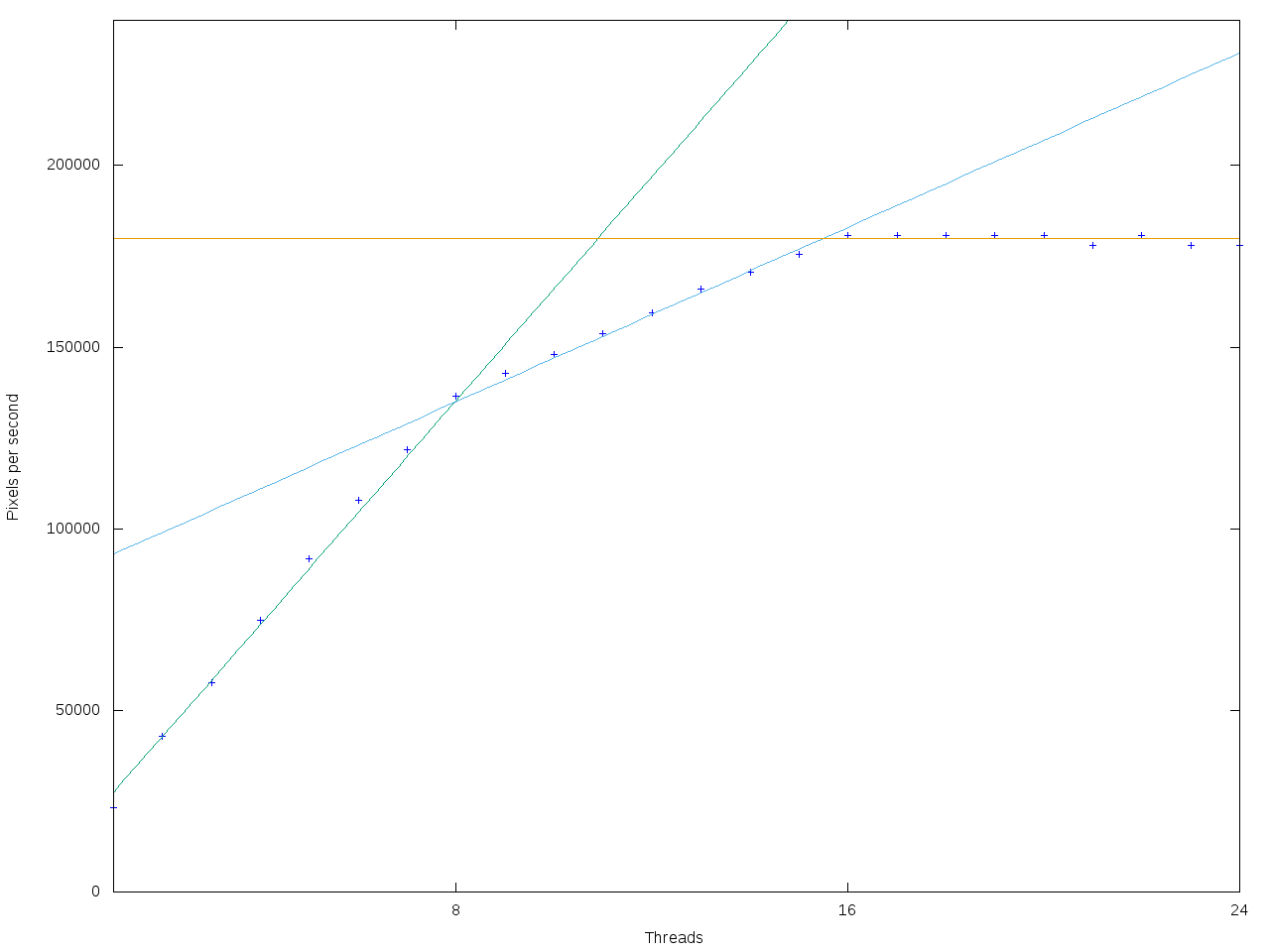
Škálování do 8 jader krásně lineární, potom do 16 také (v tomto případě je to horší, je to 32%). Ve skutečnosti jsem tento test dělal jako první, protože tuto ukázkovou scénu mám rád. Ale při renderingu si nelze nevšimnout, že poslední vlákno radiozity stále několik sekund běží, zatímco se ostatní jádra flákají a až po této pauze následuje raytracing.
Závěr
A ještě než se někdo zeptá, jo nudil jsem se. ;-) Kopíroval jsem nějaká data na NAS a co dělat jiného během čekání, než si hrát s povrayem a gnuplotem, že. Ve skutečnosti to tak dlouho netrvalo, ty rendery nahoře nejsou to, co se renderovalo během testů. Scény jsou stejné, ale nastavení na testy je jiné, snížil jsem kvalitu renderu. Na výsledky to nemá vliv, stále se použivá příslušný počet vláken, ale čekat 24x20minut na radiozitu se mi fakt nechtělo.
Co říct k výsledkům. Je skvělé, že to škáluje lineárně a to v obou oblastech. Je vidět, že procesor má při běžné práci skutečně mnoho prostředků nevyužitých a SMT je dokáže využít. 40% výkonu navíc není k zahození.
Co se týče toho, kolik vláken spawnout, není potřeba se tím příliš trápit. Udávané pravidlo N+1 už je asi přežité, některé makefily nastavují 2*N (tedy 32 vláken pro R7). Hodí se to pro případy, kdy se čeká na něco jiného, než jen na CPU. A jak je vidět, může to pomoct a rozhodně to neuškodí.
Na výsledcích to není příliš vidět, ale během renderu je to vidět krásně. Velmi rychle se v obrázku vyrenderují oblasti ve kterých „není co řešit“ a velice rychle se vychytá těch 16 vláken, které prostě trvají. Tzn ta „uklidová“ vlákna sice čas navíc nepřinesou, ale zase se to pro uživatele zobrazí o dost rychleji.
A o to možná jde, nejde o to, jak rychle to bude dokončené, ale jak rychle to uživateli připadá. Je rozhodně lepší se dívat alespoň na část obrázku, než čekat na celý výsledek.