Nedávno jsem potřeboval vyřešit poměrně jednoduchý problém. Rozbalit několik tarů obsahující adresářový strom. Jednotlivé archivy mají velikost řádově malé stovky GB, největší cca 300GB a obsahují několik stovek tisíc souborů.
Archivy obsahují adresářový strom se soubory, jejichž celkový počet je několik set tisíc, do milionu. Jsou uloženy v adresářích, kterých je několik málo desítek tisíc. Adresáře typicky obsahují max 100 souborů, průměrně mnohem méně. Nejedná se tedy o jeden adresář s milionem souborů, kde lze připustit, že by s tím mohl být problém (i když i to je poněkud zvláštní).
Úkolem tedy je tyto archivy někam (postupně) rozbalit, něco udělat s daty (to není předmětem tohoto článku) a potom ta data opět smazat. A rozbalit další archiv. Úloha je tedy poměrně přímočará: rozbalit, zpracovat, smazat, opakuj.
Pracovní dataset a pool
Vzhledem k tomu, že mám aktuálně nejvíce místa na ZFS na FreeBSD, tak jsem, nic zlého netuše, začal s touto akcí právě na ZFS. Dataset měl nastavený sync=disabled, nebylo potřeba data nijak chránit, v případě výpadku proudu a UPS lze daný archiv znovu rozbalit. Stejně tak je vypnutý atime a není použitá komprese. Tj. v zásadě nejrychlejší možné nastavení ZFS datasetu.
Zpool, na kterém tento dataset bydlí, je postaven jako 3x VDEV mirror, tedy ekvivalent raid 10 nad 6 disky. Sice se jedná o SATA 7200rpm disky, ale i tak se jedná o nejrychlejší možný zpool, kterého na daném stroji dosáhnu. Rychlost sekvenčního čtení 600MB/s, zápis kolem 450MB/s, 720 random read IOPS, 360 random write IOPS. Jasně, v době NVMe storage nic moc, ale na soukromé zpracování dat je to v pohodě.
Testovací archiv
V tomto článku budu jako testovací archiv používat následující:
| Objektů celkem | 195 762 |
| Souborů | 187 835 |
| Adresářů | 7 927 |
| Souborů na adresář | 24 |
| Velikost archivu | 148 GiB |
| Průměrná velikost souboru | 830 kiB |
Není to tedy nic, z čeho by se musel běžný FS zbláznit.
Testy na ZFS
Rychlost rozbalování nebyla nic moc, ale ještě to šlo vzhledem k tomu, že operace nad daty byla výrazně pomalejší, rozbalování příliš nezdržovalo.
Rozbalení dat na dataset se sync=standard:
| Rychlost | 72 MB/s |
| Soubory za čas | 89 souborů / s |
A na datasetu s sync=disabled:
| Rychlost | 71 MB/s |
| Soubory za čas | 87 souborů / s |
Zajímavý je ještě jeden údaj a to byl vlastně první důvod, proč jsem se na výkon ZFS z hlediska počtu souborů za čas zaměřil prve. V rámci práce potřebuju hledat soubory v daném stromu podle jména. Nic složitého, prostě jen find . -name 'filename'. Problém ovšem je, že to trvalo skoro tři minuty. Nebyl by to problém, kdyby to takto dlouho běželo jen poprvé, ale systém z nějakého důvodu ty metadata velice rychle (v rámci minut) zapomene. Netuším proč.
Zde je test find | wc -l pro oba datasety (prakticky by na to sync neměl mít vliv, protože je to čtení a ještě k tomu metadat):
| dataset sync standard | 137 s |
| dataset sync disabled | 143 s |
Takže téměř pokaždé, když chcete udělat find (nad necelými 200tis soubory!) si počkáte přes dvě minuty. (Testovací archiv je skoro rok starý, pro aktuální dataset s více soubory je toto číslo ještě větší.)
Další a největší problém ale nastal u mazání tohoto pracovního stromu. Pro menší archivy (cca 30GB) byla rychlost rm -rf workspace dokonce pomalejší, než rozbalení archivu. Ano, vytvořit cca 200tis. souborů o celkové velikosti cca 30GB je pro ZFS jednodušší úkol než jejich postupné smazání.
Rychlost mazání pracovního archivu na ZFS:
| dataset sync standard | 1979 s | 95 souborů / s |
| dataset sync disabled | 2179 s | 86 souborů / s |
Takže rychlost mazání je srovnatelná s rozbalováním archivu. Rychlost mazání souborů je necelých 100 / s na min. 360IOPS. Což je docela tristní.
Když bych si měl zaspekulovat (ale zcela jistě to takto není, viz další text), tak to vypadá, že i rychlost rozbalování archivu je limitovaná nikoliv rychlostí zápisu dat (ten zpool umí být 5x rychlejší), ale možná zápisem metadat pro každý soubor.
Při hledání na webu jsem narazil jen na obecné odpovědi typu prostě je to pomalé bez nějakého relevantnějšího výsledku.
Řešení, které se přirozeně nabízí, je vytvořit nový dataset, rozbalit tam archív a po zpracování tento dataset smazat. Tato operace je z hlediska userspace “hned” (při nastavení feature@async_destroy=enabled na daném poolu), ovšem ani zfs nemá příliš mnoho práce s uvolněním datasetu z poolu. Na rozdíl od mazání jednotlivých souborů.
Narazil jsem ještě na jedno další a hodně neintuitivní a zajímavé možné řešení. A tím je udělat clon daného datasetu, v tom clonu smazat ty soubory (pokud nechceme smazat celý dataset) a potom smazat původní dataset a jeho snapshot. Zdá se to jako blbost, FS musí mít víc práce se záznamy který blok do kterého clonu patří.
No ale vyzkoušel jsem to:
| ZFS clone | 445 s | 442 souborů / s |
Takže mazání souborů z clonu je rychlejší (cca 4x) než mazání souborů z původního datasetu. Velmi zajímavé.
Obecně je dobrá rada používat všech vymožeností, které nám daný FS nabízí, takže pokud víme, že bude potřeba nějakou část dat rychle smazat, můžeme jej umístit na vlastní dataset (nebo obecně na vlastní FS) a vyřešit to tímto způsobem. Ale opravdu je nutné, aby rychlost mazání probíhala takto pomalu?
XFS na pomoc
Vrtalo mi to hlavou, tak jsem si vzal na pomoc linux a XFS, který po obrovské rekonstrukci v roce 2012 vynikající přednáška, umí s metadaty pracovat velmi rychle.
Takže jsem si vzal volný 3TB disk (stejného typu a rychlosti jako v zpoolu), udělal 320GB oddíl (disk dosahuje nejvyšší přenosové rychlosti na okraji, takže malé oddíly vytvářené na počátku disku jsou obecně velmi rychlé) a naformátoval na XFS bez jakýchkoliv dalších optimalizací. A na tento jeden disk (tj s třetinovou rychlostí zápisu oproti zpoolu) jsem rozbalil archiv. A nestačil se divit.
Všechny testy na XFS přehledně v jedné tabulce:
| Rozbalení archivu | 94 MB/s | 116 souborů / s |
| Mazání archivu | 57 s !!! | 3295 souborů / s |
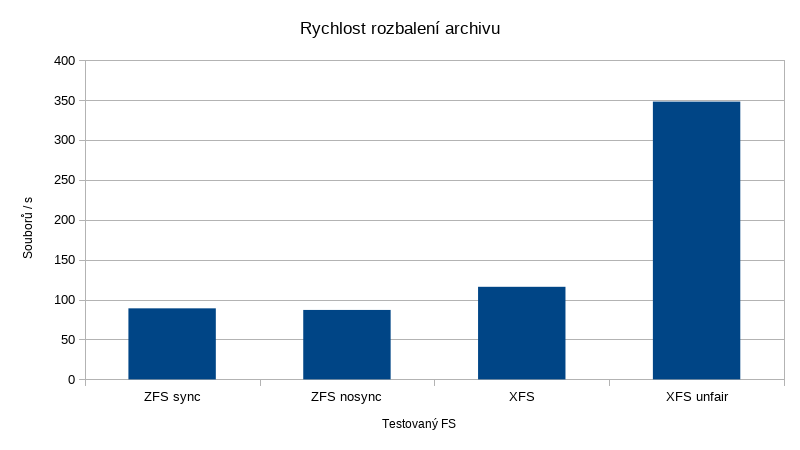
Zatímco na ZFS trvá mazání adresářového stromu cca 2000s, tady je to hotové za 57s, tedy 35x rychleji. A to ještě za situace, kdy XFS je na jednom disku, zatímco zpool tvoří de facto raid10 nad šesti disky a jeho výkon v zápisu by měl být 3x vyšší.
Grafy
Nejprve si ukažme srovnání rychlostí rozbalovaní archivu z hlediska počtů souborů za čas:
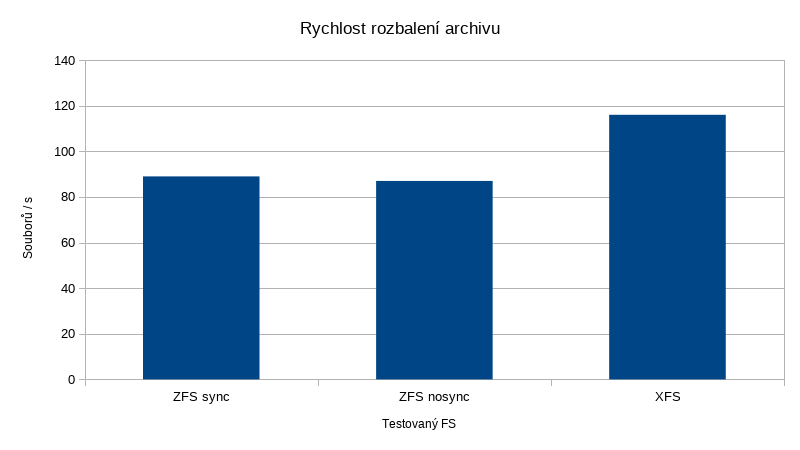
Pokud připustíme, že ZFS má k disposici 3x větší diskový výkon (což je z mnoha důvodů dost diskutabilní tvrzení a docela nefér srovnání), vypadalo by to následovně:
A konečně porovnání rychlosti mazání daného archivu:
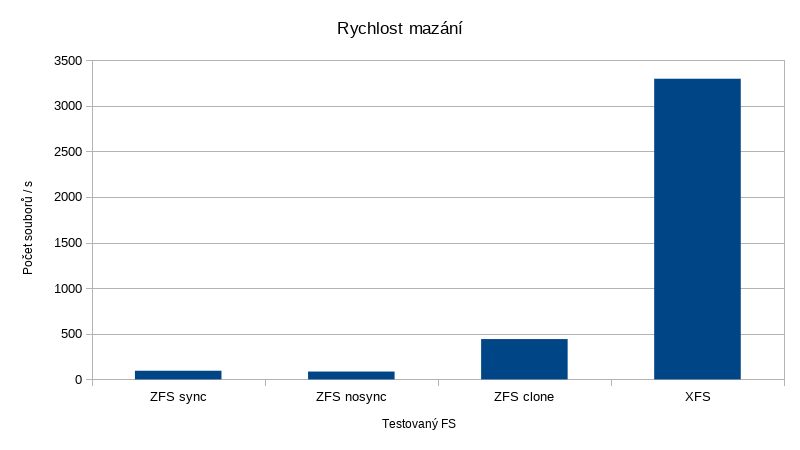
Nefér srovnání rychlosti mazání zde nemá smysl uvádět, to by tam výsledky ZFS nebyly ani vidět.
Závěr
Vlastně to celé začalo docela nevinně, zkoumal jsem, proč je find nad těmito daty tak pomalý (Z hlediska FS se vlastně jedná o ideální stav, žádný adresář není přeplněný soubory, indexy jsou malé a rychlost procházení by měla být maximální. Ale není.). Na to jsem zatím nepřišel, jen mám seznam nepotvrzených hypotéz (například velký počet snapshotů nebo vůbec jejich přítomnost na datasetu). V rámci urychlení findu jsem testoval i vliv SSD cache. Bez výsledku, dokonce to bylo horší. Cache jsem nastavil pouze na metadata, viděl jsem (v zpool iostat) jen zápis. Nikdy ne čtení. Ten systém z nějakého důvodu zahazuje metadata adresářů z paměti i z cache.
Takže to jsem nevyřešil a objevil se další, větší, problém. Rychlost mazání souborů na ZFS. Na webu jsem našel jen odkazy „ano, je to pomalé, vyhněte se tomu“. A to je vlastně i poselství tohoto článku. Tento článek neměl být kritikou ZFS. Každý systém má své quirky a nevyhnou se ničemu a nikomu.
Výkon XFS je pozoruhodný. Srovnání není úplně fér, protože XFS je FS staré generace a ani omylem neposkytuje totéž co ZFS, to je nutné vždy brát v ohled. Asi se tady sešly dva extrémy, jeden FS, který má se změnou metadat problém a druhý, který to v roce 2012 vyřešil.