V minulém článku jsem se dotkl výkonu ZFS na FreeBSD a to v úloze mazání většího množství (malých) souborů. Ve skutečnosti to ale není ten hlavní problém, který mě na ZFS trápí. Jak již bylo napsáno, mazání pracovního adresáře lze hravě vyřešit tak, že jej budeme vytvářet jako samostatný dataset, který na konci práce smažeme celý.
Hlavní problém, který aktuálně řeším (a TLDR: ani v tomto článku jej nevyřešíme) je pomalý průchod adresářovým stromem. Viz ukázka:
$ time find . | wc -l
344666
real 4m44.282s
user 0m0.372s
sys 0m2.861s
Což je jen dost těžko akceptovatelné a navíc za situace, kdy OS z nějakého důvodu tato metadata po chvíli (do 20 minut, přesněji jsem to nehlídal), zapomene a při dalším find opět čekáte 4 minuty. Což je zajímavé samo o sobě, lze asi akceptovat, že se z cache musí odstranit část metadat, ale jistě ne pro celý tento adresářový strom.
Tohle bohužel nemá tak přímočaré řešení jako problém s mazání, které lze vyřešit vlastním dočasným datasetem. V tomto případě, kdy je nutné občas prohledat (měnící se) adresářový strom pro nějaké jméno by se jistě našlo řešení v podobě indexu jmen, ale to by ovšem znamenalo, že všechny nástroje pracující na tomto stromu by muselo tento index měnit. Potom ovšem padá jakýkoliv důvod přímo používat a lze mít data v DB.
Á propós:
add=> \timing
Timing is on.
add=> select count(*) from files;
count
106407926
(1 row)
Time: 36456.988 ms (00:36.457)
Tabulka files obsahuje metadata k těm 106mil. souborům a dotaz, který vede na full table scan, je prakticky stejný jako ten find | wc -l. DB to zvládá rychlostí téměř 3 miliony záznamů za sekundu. Běží na stejném zpoolu jako výše testovaný zfs dataset. Ten to zvládá rychlostí 1213 souborů / s. Tedy 2.5 tisíckrát pomaleji.
Zarážející je, že z těch 4m44s jen cca 3s jsou v systému. Zdá se, že OS čeká na něco. Ale na co? Na disky? Nezdá se. Podle zpool iostat -v se disky nudí. Celý zpool má během „operace find“ 183 IOPS, což je 3x méně, než by mohl mít, pokud by disky byly zatížené na 100%:
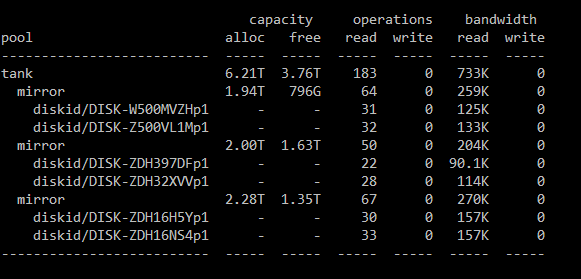
Disky, zdá se, běží na 30% max svých možností. Podívejme se na iostat -x:
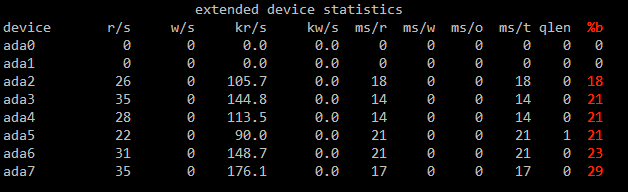
Ten to jen potvrzuje. Disky zpoolu jsou vytížené kolem 20%, maximálně 30%.
Jak jsem prozradil už na počátku, nevím, čím je to dané. Disky jsou zdravé a v jiných operacích podávají očekávaný výkon. Nemám nic pořádného v ruce, jen několik nepotvrzených hypotéz.
Jednou z těchto hypotéz, která mě napadla už u minulého článku, zda je výkon zpoolu skutečně takový, jak si představuji. Jedna věc je počítat hrubý výkon šesti disků a jiná věc je potom skutečný výkon v reálném provozu. Takže jsem otestoval sekvenční čtení (cat soubor > /dev/null) a výsledek kolem 400-500MB/s je očekávaný a v pořádku. Tady tedy problém nebyl. Ovšem opakované čtení stejného souboru dávalo stejné výsledky. ZFS jej vůbec necachoval ani po dvaceti čteních. Ano, ARC pracuje složitěji než klasické cache, ale že by ji ani dvacet čtení nepřesvědčilo, je divné.
Takže jsem stejný soubor přesunul na UFS2 a otestoval tam. Šel okamžitě to cache. Potom zpět na ZFS. A dvě čtení stačí na přesun do ARC. Zdá se tedy, že něco v historii zpoolu, zfs, datasetu nebo způsob vytvoření toho konkrétního souboru zabránilo ARC v jeho cachování. Nevím. Jen nepotvrzené hypotézy.
Jen na okraj. Porovnání rychlosti čtení z FreeBSD cache a z ZFS ARC: Pokud už se soubor dostane do ARC, rychlost čtení na daném stroji (fx8350) je 2.15GiB/s. Rychlost čtení z FreeBSD cache (pro UFS2): 3.75GiB/s. ARC je složitější, zatímco FreeBSD cache je nativní a roky optimalizovaná. Jenže rychlost čtení 2GiB/s se dá dneska dosáhnout i z levných NVMe disků. Jasně, je to porovnání opět mimo mísu, protože tento stroj (2013 FX8350) podporou NVMe rozhodně netrpí, na druhou stranu je taková rychlost „RAM“ cache k zamyšlení. Zejména, když nativní cache je skoro 2x rychlejší.
Pár slov na závěr. Už při psaní minulého článku během testů odstraňování souborů jsem si uvědomil jednu věc. Zbytek systému bez problému běží dál jako by se nechumelilo. Vlastně tomu odpovídá celá moje zkušenost s FreeBSD od samého počátku. Ten systém prostě běží vlastním tempem a prakticky žádná operace jej nezablokuje (ještě se mi to cíleně nepodařilo). To, že se někde 40 minut maže adresářový strom vlastně nic neznamená, jaily běží dál, zfs send si jede de facto nezměněnou rychlostí, data přes sambu a nfs jsou dostupná. Na linuxu se mi několikrát podařilo systém zablokovat přes náročné IO, mnozí uživatelé mají špatnou zkušenost s kopírováním na USB flash disky (příčinou je příliš velká dirty cache a příliš pomalý usb disk), apod. Z tohoto ohledu je FreeBSD mnohem plynulejší. Možná je to způsobeno nedokonalostí IO scheduleru, který (další nepotvrzená hypotéza) raději vkládá prázdné cykly než aby zabil IO pro zbytek systému, možná je v tom něco jiného. I tento ZFS běží perfektně a funguje skvěle pro reálné programy (db během toho full table scanu četla 350MB/s), odstraňování se dá obejít smazáním celého datasetu a takto velký adresářový strom má mít stejně index (a upřímně, v mém uvažování stejně patří do DB).