V minulém článku jsme si ukázali nějaké základní statistiky z ukládání stránek. Dneska si statistiku lehce rozšíříme, ukážeme si histogramy a zamyslíme se nad komprimací dat v DB.
Několik základních údajů
Nejprve počty:
- Počet souborů: 40,062,135
- Počet unikátních souborů: 1,580,772
- Počet stažených stránek: 350,324
Minule, v červnu, to bylo 31 mil. souborů, za nějakých 5 měsíců nárůst o 10 milionů souborů. Počet unikátních souborů narostl o 400 tisíc. Stále se tedy pohybujeme někde na úrovni 4% unikátních souborů na stránce.
A souhrnné velikosti:
- Velikost unikátních souborů: 66.5 GiB
- Velikost všech stránek: 367.5 GiB
Takže nárůst od minula nějakých cca 30GB. Tj tedy 6GB/měsíc. (Tyhle kinetické statistiky berte s rezervou, to není tématem tohoto článku.)
Průměry:
- Průměrný počet souborů na stránku: 114.4
- Průměrná velikost unikátního souboru: 44.1 KiB
- Průměrný počet unikátních souborů na stránku: 4.5
- Průměrná velikost dat na stránku: 1.1 MB
- Průměrná velikost unikátních dat na stránku: 199.1 KiB
Prakticky beze změny. Lehce klesly velikosti jedné stránky a unikátních dat na stránce, ale to může být dáno zejména tím, jaké další odběry jsem do RSS přidával.
Ukládání dat do PG
Tématu ukládání velkých dat do Postgresu jsem se již v minulosti několikrát věnoval (1, 2). Nechci to nijak šířeji rozebírat, jen upozorním na jednu věc, na kterou se často zapomíná. Postgres všechna data větší než 2kiB komprimuje. Transparentně, používá se rychlý alg. lzop, který sice nedosahuje extrémních komprimačních poměrů, ale data, která zkomprimovat lze, zkomprimuje přiměřeně dobře a velmi rychle.
Takže v praxi:
- Velikost unikátních souborů: 66.5 GiB
- Velikosti tabulky s daty: 54.0 GiB
- Komprimace v PG ušetřila: 12.6 GiB
Což je komprimační poměr na tímto typem dat (nejvíc mají obrázky apod.) 18%. Což není špatné. Tedy je opravdu vhodné zvážit, zda velká binární data mít na FS (kde transparentní komprimaci poskytuje jen BTRFS), nebo v DB, kde se komprimují by default.
Histogramy
Průměr není celý příběh, průměry klamou. Můžeme si vypočítat další statistické hodnoty, medián, standardní odchylky apod., nejlepší (imho) a nejnázornější formou statistiky je histogram.
Histogram je taková ta věc, jak máte na ose X (to je ta vodorovná) několik chlívků a, každý chlívek má svůj rozsah. Vstupní data se rozhážou do jednotlivých chlívků dle rozsahu kam patří, úplně na konci se spočítá počet věcí v každém chlívku a vynesou se do sloupečků na osu Y.
Počet souborů na stránku
Průměrnou hodnotu už známe, to je těch asi 115.
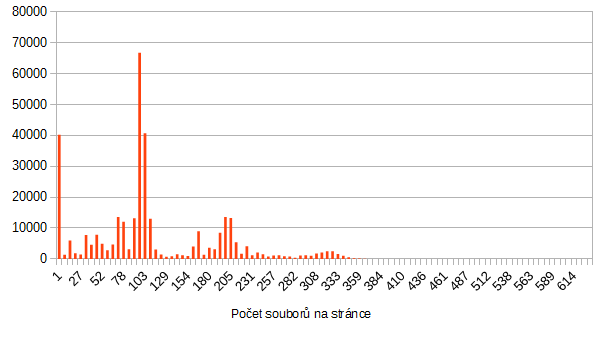
Jenže 40 000 stránek má počet souborů 1-7 (první chlívek), potom celkem nic moc, potom nárůst kolem průměru. A jedna stránka má 634 souborů.
Velikost unikátních souborů
Na následujícím šokujícím grafu vidíme statistiku počtu souborů v závislosti na velikosti:
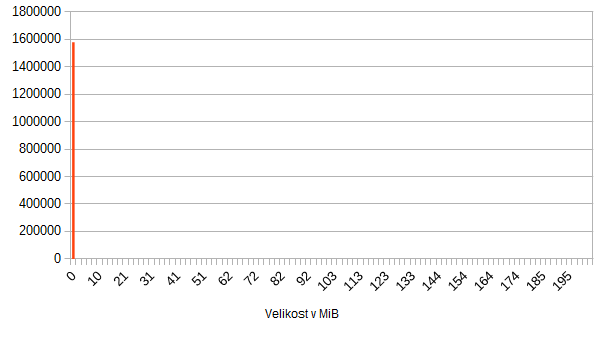
Super ne :-) Drtivá většina souborů je menší než 2MB, a jeden jediný soubor tento graf natáhl na 200MB.
Když to 40x zazoomujeme:
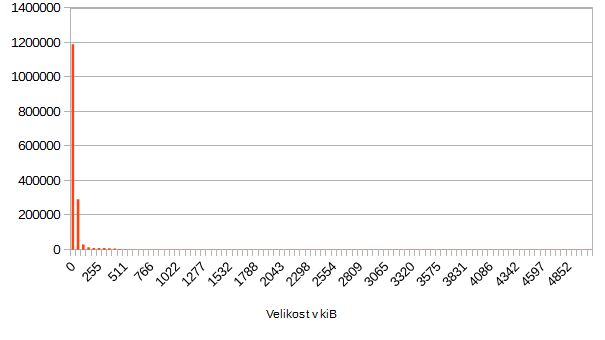
Tak pořád nic nevidíme. Drtivá většina (přes milion z 1.5 mil. souborů je menší než 50kiB). Takže ještě 10x:
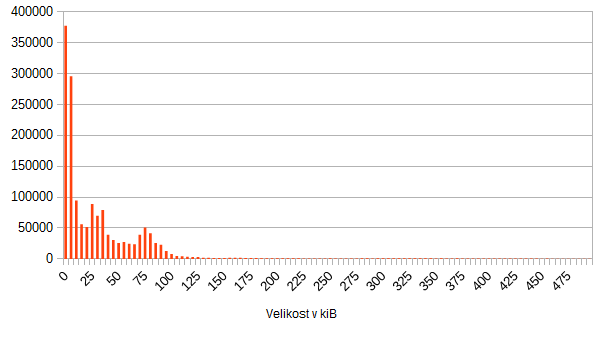
Takže konečně, zajímavé počty souborů mají velikost menší než 100kiB. Tak ještě trošku:
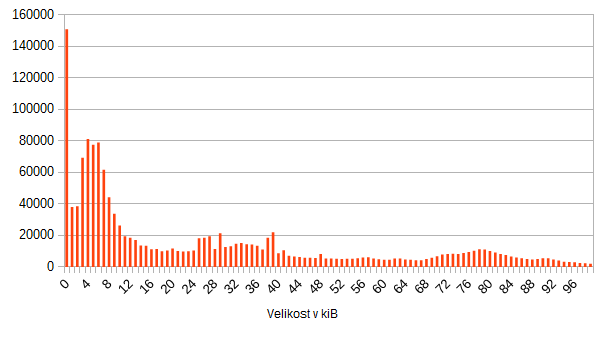
Připomínám, že průměr je 44 kiB.
Uzávěr
- 10% všech souborů stahovaných z webu (v tomto testu) má velikost menší než 1 kiB.
Mimo jiné také odtud plynou všechny ty snahy o SPDY a HTTP2. Protože při takto malých objemech a při takto velkých počtech (115) je každé HTTP spojení velmi drahé a znamená nezanedbatelné náklady navíc.
- 96% všech dat stahovaných z webu je duplicitních
Tohle je poměrně smutné číslo uvážíme-li, že cachování je na moderním webu prakticky kompletně potlačené (pragma no-cache, valid until 1970 apod. praktiky), správně fungující cachující proxy a vlastně ani prohlížeč nemají co cachovat.