Nevím nakolik používáte záložky v prohlížečích. Kdysi jsem je používal, měl jsem odkazy na stovky zajímavých stránek. Jenže po létech člověk zjistí, že: 1/3 celých domén už vůbec neexistuje, 1/3 konkrétních url neexistuje (třeba proto, že se změnil redakční systém a nikdo si nedal práci s rewrite původních url) a zbylá 1/3 stránek sice existuje, ale má úplně jiný obsah než před těmi roky. Záložky jsou tedy celkem k ničemu, protože neukládají stránku v čase založení záložky (srovnejte si to s knihou).
Prohlížeče nabízejí uložení stránky na disk. Formát příliš jednotný není, některé prohlížeče umí uložit stránku do jednoho souboru (který potom sami umí zobrazit), jiné mají soubor.html a vedle toho složku s dalšími soubory (takže pokud s těmito dvěma objekty nezacházíte stejně, tak vám zůstanou html bez dalších souborů). Takže sice lepší, ale taky nic moc. Nejlepší způsob jak si uložit stránku v prohlížeči je vytisknout si ji do PDF.
A to ještě nehovořím o situaci, kdy zmizí celá doména, stovky stránek. Tady webové prohlížeče nemají odpověď vůbec žádnou.
Pravěk
Před dávnými časy jsem si na tuto úlohu napsal bash skript, který s pomocí wgetu stahoval stránky do adresářů a ty potom ukládal do tar archivů. Do vedlejšího souboru se dále ukládala URL daného archivu. Nějakou dobu to stačilo.
Společně s tím se, opět pomocí wgetu, stahoval celý web (mirroring), pokud byl zajímavý.
Když tímto způsobem počet souborů rostl, přestala být tato metoda efektivní.
Středověk
Bash skript nahradil Python skript. Stále se data stahovala pomocí wgetu (o implementaci v pythonu jsem se ani nepokoušel), stále se dávala do tar archivů.
Podstatným kvalitativním zlepšením bylo, že archivy a metada se neukládaly na disk, ale do databáze. V db byly tedy metadata (url, title stránky, kdy byla stránka stažena apod.) a vedle toho data tar archivu.
Dalším zlepšením bylo provázání s RSS čtečkou TinyTinyRSS. Do tabulky url ke stažení se kopírovala url článků z rss čtečky. Přichází automatizace, stránky se stahují tak jak je rss čtečka detekuje z feedů.
Moderna
Takhle by to docela dobře mohlo fungovat i dál. Jenže každého napadne, že pokud se stahují stránky a ukládají se do archivů, bude každý archiv obsahovat hromadu sdílených dat (logo stánek, css styly, js apod.). Disky nerostou na stromech, takže když se velikost db zvětšila nad psychologickou mez (což je přesně 343 GiB ± 1024 MiB) správce db systému (což je shodou okolností stejný člověk jako autor programu i tohoto textu), tak napsal bugreport na vývojáře, aby se to deduplikovalo.
Takže jsme to deduplikovali (pomohl profesor Samo Seto). Implementace opět zcela přímočará. Dva stejné soubory se poznají tak, že mají stejnou hash.
Tohle mě bude ničit až do konce života. Pro hašovací funkci h platí relace: h(x) ≠ h(y) → x ≠ y ; x = y → h(x) = h(y). Jenže, toto jsou relace implikace, které nám vůbec nezavádí ekvivalenci. Tedy, pokud se hodnoty haš. fcí shodují, nemůžeme psát, že se shodují i ty argumenty. Ve skutečnosti (protože mohutnost množiny obrazů je mnohem menší než mohutnost množiny vzorů) existuje nekonečně mnoho případů, kdy platí h(x) = h(y) pro x ≠ y!
Kryptografické hašovací funkce se konstruují pro reálná data, tam je riziko malé (pro SHA512 je matematická pravděpodobnost nalezení kolize (dvou různých souborů se stejnou haší) 10-77 což je v reálném světě docela blízko nule.
Takže takže se ukládají pouze data souborů s unikátním hodnotou SHA512 (SHA2 512/512).
Tato akce proběhla v minulých dnech a přinesla s sebou několik zajímavých čísel.
Statistika
Nejprve pár přímých dat:
- Počet archivů: 250‘846
- Velikost archivů: 368’587’311’600B (343 GiB)
Celkový počet uložených stránek je tedy cca čtvrt milionu a jejich velikost je 343 GiB.
- Počet souborů celkem: 31’102’935
- Počet unikátních souborů: 1’224’986
- Velikost unikátnich souborů: 56’027’420’806B (52 GiB)
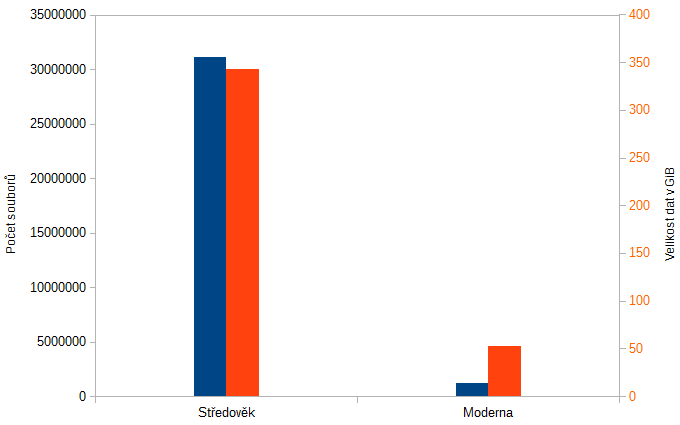
256 tis. stránek nám obsahuje 31 milionů souborů, z toho je jen mega unikátních. Unikátní soubory mají cca 50 giga.
Teď si přivoláme na pomoc starou dobrou aritmetiku:
- Průměrná velikost archivu s webem: 1’469’376B (1‘434 kiB)
To znamená, že když si v prohlížeči zobrazíme průměrnou stánku (no průměrnou, ty stránky moc globálně průměrné nejsou, tady se jedná o stránky, které mě nějakým způsobem zajímají a ještě je mám v RSS), tak stáhneme více než 1 mega dat.
- Průměrný počet souborů na stránku: 124
- Průměrný počet unikátních souborů na stránku: 4.9
- Počet všech souborů vs. počet unikátních souborů: 25.4
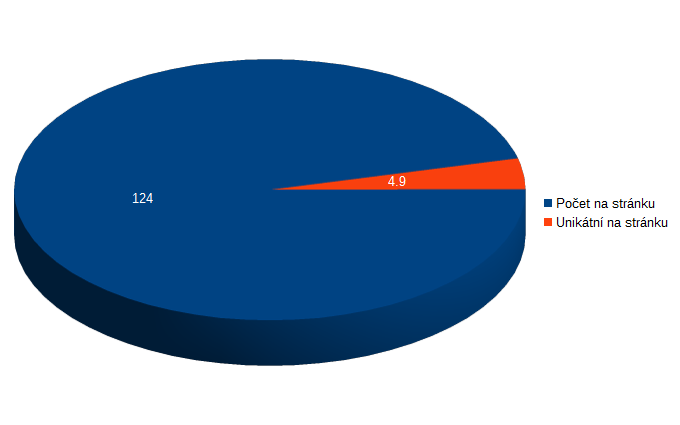
V tom staženém jednom mega na stránku se nám průměrně schovává 124 souborů!!! Z toho dostaneme pouze 5 souborů, které jsme dosud neviděli.
- Průměrná velikost unikátního souboru: 45’737B (44 kiB)
- Unikátní data na jedné stránce: 223’353B (218 kiB)
- Velikost všech souborů vs. velikost všech unikátních souborů: 6.6
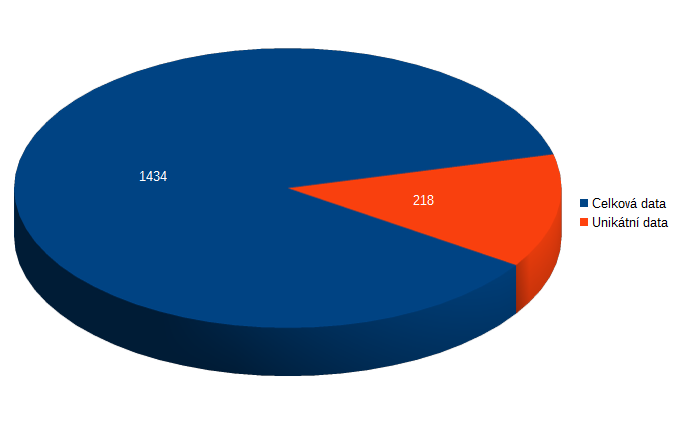
V průměrné stránce tedy dostaneme cca 5 souborů, které jsme nikdy neviděli, to znamená celkem nových 218 kiB dat (v tom 1.4 mega). Tedy asi 85 % dat stránek je sdílený obsah.
Příběhy z natáčení
Na tuto akci jsem se velmi těšil. Přece jen překopat 300 giga ve 31 milionech souborech, to se neděje každý den.
Opětovně se ukázalo, že nelze mít na FS všechna data (rozbalené archivy). Pro FS je těch 31 milionů souborů ve 250tis. adresářích opravdu problém a jen BTRFS metadata narostla asi o 34GB (1KB na soubor?). FS to zvládl, ale s 250 tis záznamy v jednom adresáři se nepracovalo snadno.
Naopak pro DB nebyl žádný problém mít 250tis záznamů a 343GB (jako BYTEA), stejně tak není žádný problém mít 1.2M záznamů a 50GB v BYTEA.
Čekal jsem problém u 31M záznamů (metadata o souborech), tedy insert a update indexu. V praxi se však ukazuje, že ani toto není problém (přesná měření nemám, ale celkový čas uložení stránky do db zabírá wget, zatímco samotné uložení do db je pod rozlišovací hranicí (200ms). Tento čas bude postupně narůstat, není však problém tabulku rozsekat do více menších.
Je potřeba si dávat pozor na analyzátory logů a vůbec logování jako takové. Používám pgBadger, ten si vynucuje nějaký formát řádku logů a také co se má logovat (všechno včetně argumentů). To znamená, že v průběhu akce se do logů dostalo ve více než 30 milionech řádků 340GB v escapované podobě. Potom běh analyzátoru trvá také o něco déle než obvykle. Toto nepředstavuje žádný problém, jen je potřeba myslet na místo na disku pro logy (případně logování během migraci zmírnit).
Stejně tak u online backup (používám pgBarman, ale tj celkem jedno), je třeba počítat s tím, že se v průběhu migrace všechna data přes WAL logy dostanou na zálohovací server. Někdy může být vhodnější před migrací online backup vypnout a po migraci udělat nový base backup (který bude o dost menší, než predchodí + všechny waly z průběhu migrace).